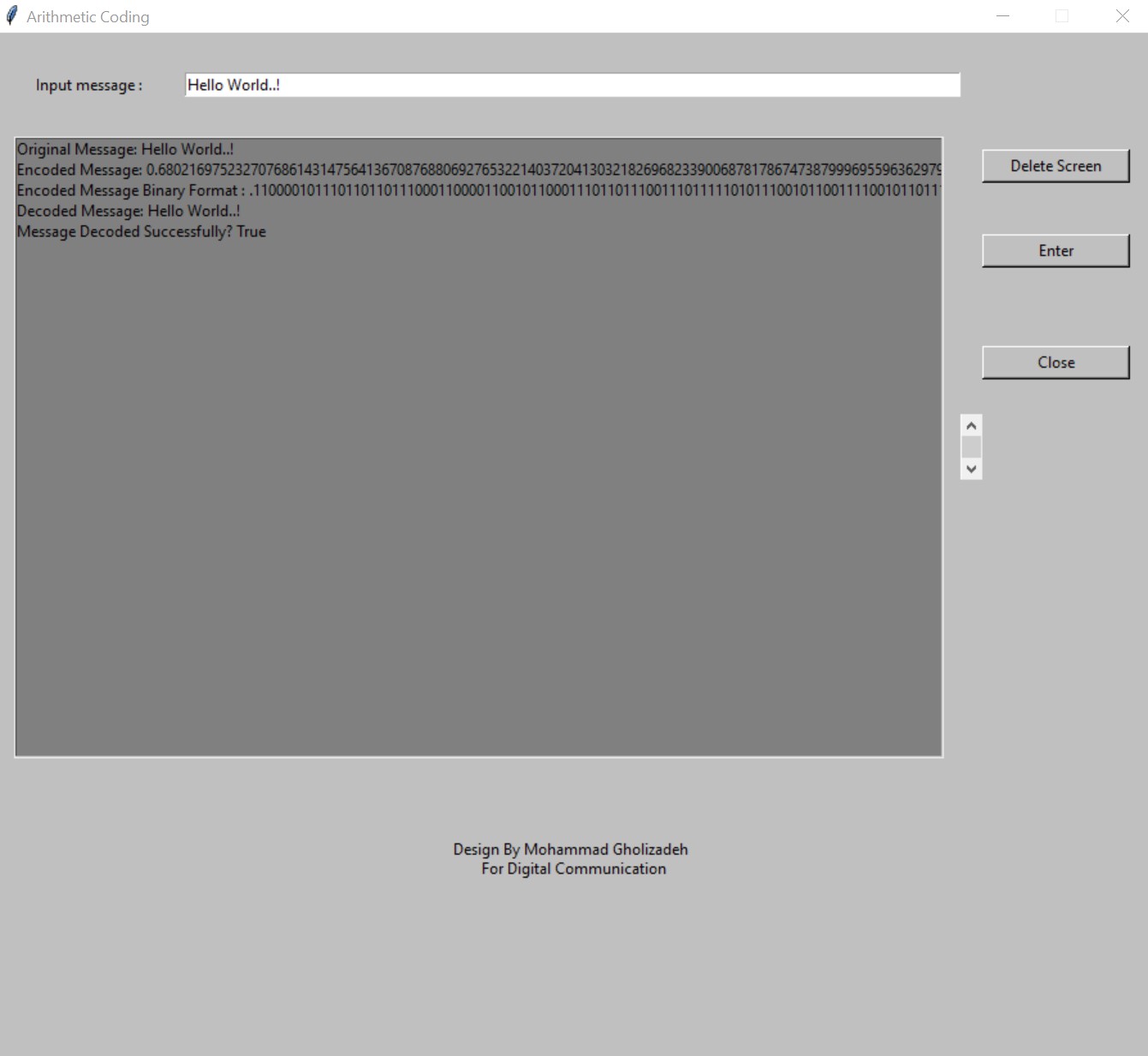
One of the methods of source coding based on entropy is Arithmetic coding. Arithmetic coding is a newer coding method that usually yields better results compared to Huffman coding. In Huffman coding, each symbol is typically assigned a code word, with a specific number of bits allocated for it. In contrast, in Arithmetic coding, the entire data can be encoded with a single numeric value. For each symbol, an occurrence probability and a corresponding range in the data are considered. The encoded equivalent of each data is represented by a number within the range of zero to one. This range is determined based on the order of the symbols and the corresponding interval for each. As the symbol length increases, the interval will also become narrower.
Now, let's examine the process of arithmetic coding with an example.
Encoding:
Suppose we want to encode the message "abc" according to the frequency table below. First, we determine the probability of each symbol according to the following formula:
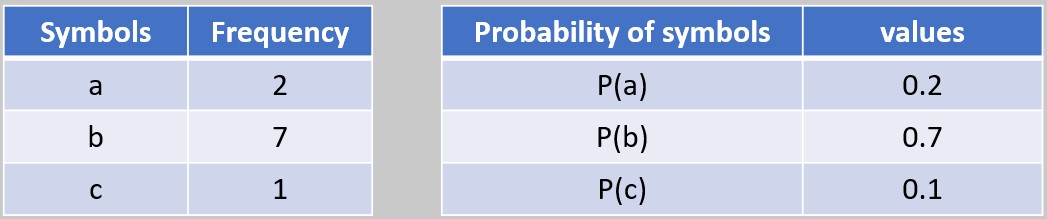
Now, using the following equation, we obtain the values of the intervals:
S: Cumulative sum of all previous probabilities.
P(X): Symbol probability.
R: The line interval calculated by the difference between the start and end points of the line, starting from point 0 and ending at point 1. Therefore, initially, R = 1-0 = 1.
L: The length of the message. (The number of symbols in the original message).
The number of steps required to calculate the intervals is equal to Stages = L + 1.
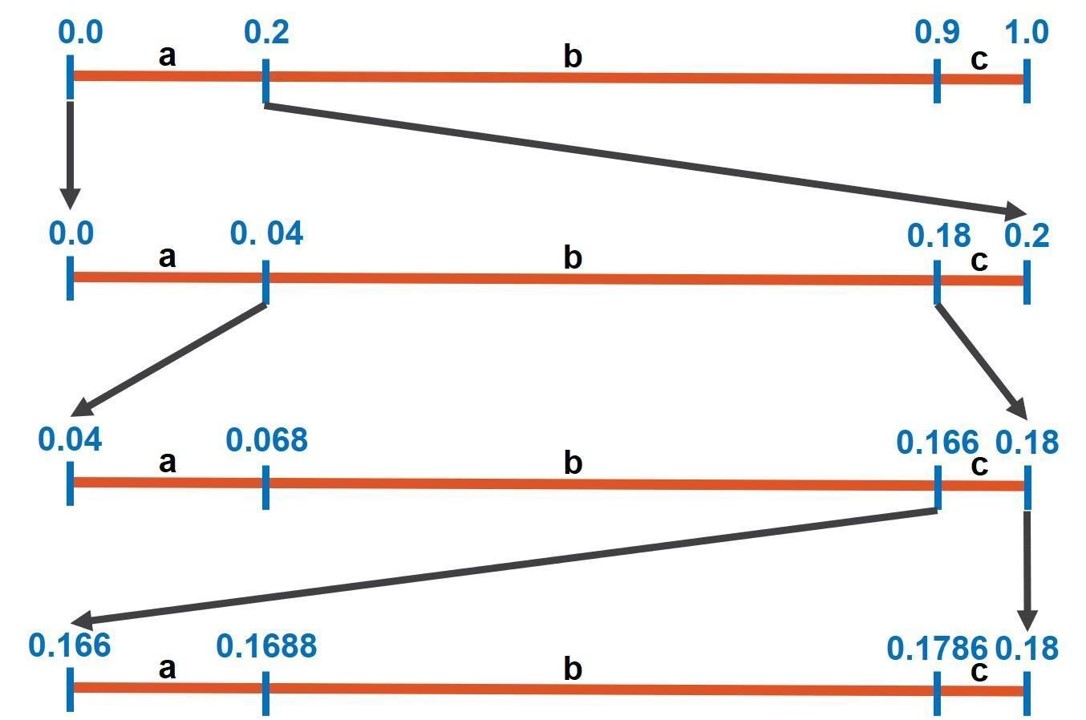
In the first step, we have:
- a : 0.0 --- 0.0+ (0.2) * 1 = 0.2 ---------> (0.0 , 0.2)
- b : 0.2 --- 0.2 + (0.7) * 1 = 0.9 ---------> (0.2 , 0.9)
- c : 0.9 --- 0.9 + (0.1) * 1 = 1.0 ---------> (0.9 , 1.0)
Note: The beginning of each interval is the end of the previous interval.

In the second step, we have:
The first symbol in the message is 'a', so the new R is obtained based on the new interval for the symbol 'a':
- a : 0.0 --- 0.0+ (0.2) * 0.2 = 0.04 ---------> (0.0 , 0.04)
- b : 0.04 --- 0.04 + (0.7) * 0.2 = 0.18 ---------> (0.04 , 0.18)
- c : 0.18 --- 0.18 + (0.1) * 0.2 = 0.20 ---------> (0.18 , 0.20)
Each symbol takes a portion of the line, and its length is equal to its probability. For example, for the symbol 'b', we have:

In the third step, we have:
The second symbol in the message is 'b', so the new R is obtained based on the new interval for the symbol 'b':
- a : 0.04 --- 0.04+ (0.2) * 0.14 = 0.068 ---------> (0.04 , 0.068)
- b : 0.068 --- 0.068 + (0.7) * 0.14 = 0.166 ---------> (0.068 , 0.166)
- c : 0.166 --- 0.166 + (0.1) * 0.14 = 0.18 ---------> (0.166 , 0.18)

In the fourth step, we have:
The third and last symbol in the message is 'c', so the new R is obtained based on the new interval for the symbol 'c':
- a : 0.166 --- 0.166+ (0.2) * 0.014 = 0.1688 ------> (0.166 , 0.1688)
- b : 0.1688 --- 0.1688 + (0.7) * 0.014 = 0.1786 -----> (0.1688 , 0.1786)
- c : 0.1786 --- 0.1786 + (0.1) * 0.014 = 0.18 ----> (0.1786 , 0.18)
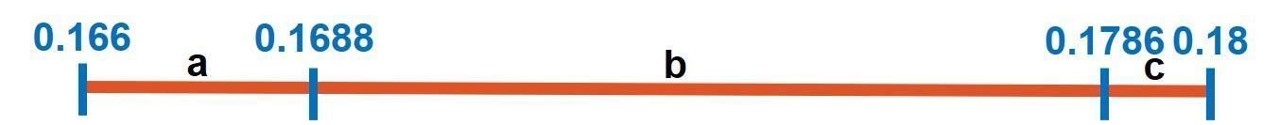
Therefore, the final interval is obtained:
Based on the last interval obtained (0.166, 0.18), any value within this interval can be used to encode the message. For example, we choose the average value:
Therefore, according to the frequency table above:
Note that if the frequency table changes, the encoded message value will also change. Up to this point, the encoding process has been completed.
Decoding:
Now we begin the Decoding stage. The inputs, or the required data, are as follows:
- Encoded message value
- Frequency table (the same frequency table used in encoding)
- Number of symbols in the original message
Step 1:
Calculating the probabilities of symbols.
Step 2:
According to the equation, the intervals are recalculated: S + P(x) * R
The value 0.173 falls within the interval (0.0, 0.2). Therefore, the first symbol in the encoded message is 'a'.

The value 0.173 falls within the interval (0.04, 0.18). Hence, the second symbol in the encoded message is 'b'.

The value 0.173 falls within the interval (0.166, 0.18). Therefore, the third symbol in the encoded message is 'c'.

Considering that the number of symbols in the original message was 3, the encoding process is complete, and the message is as follows:
The general overview of the steps:
Simulation:
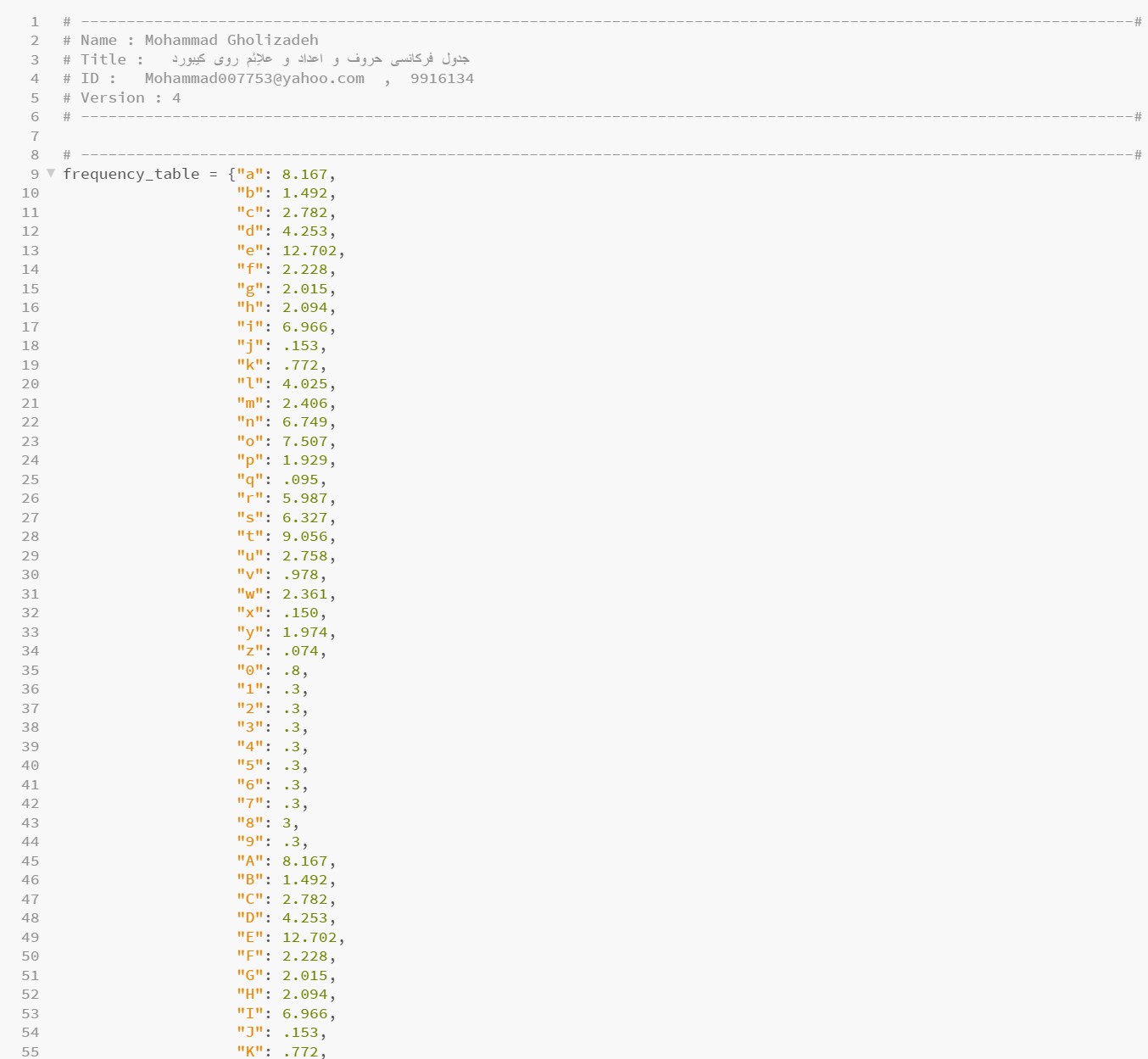
Simulation based on the general frequency table for letters, numbers, and Latin symbols for long texts is provided below. Additionally, simulation based on a custom frequency table for limited texts with a few specified characters, as shown in the example, is also presented. Furthermore, an application designed to run on the Windows operating system is ultimately developed, and images related to it are provided below. All simulations are implemented in Python.
The Python code related to arithmetic coding and encoding for the user-defined frequency table:
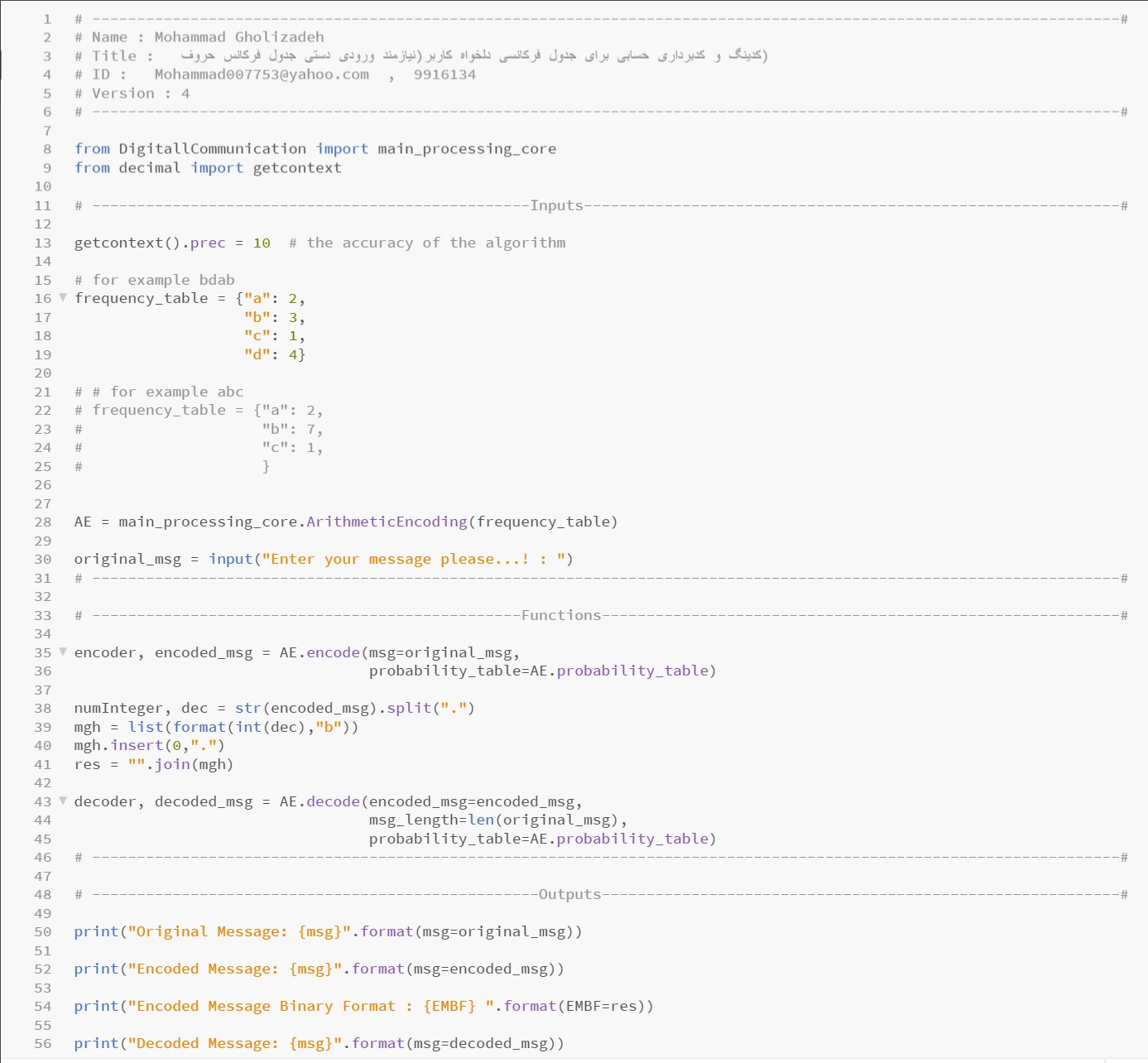
Part of the Python code related to arithmetic coding and encoding for main processing core:
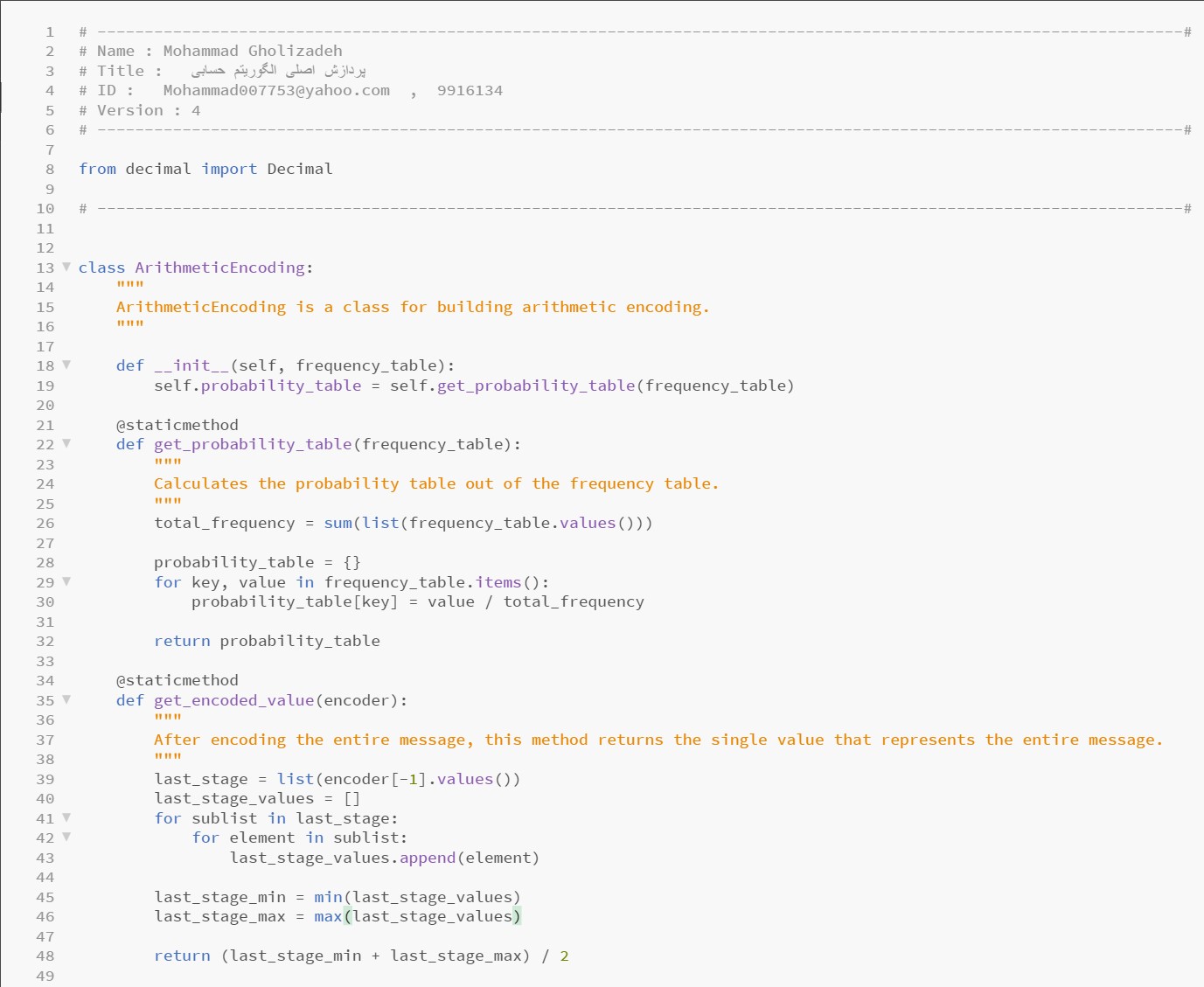
The Python code related to arithmetic coding and decoding for long texts and with a predefined frequency table:
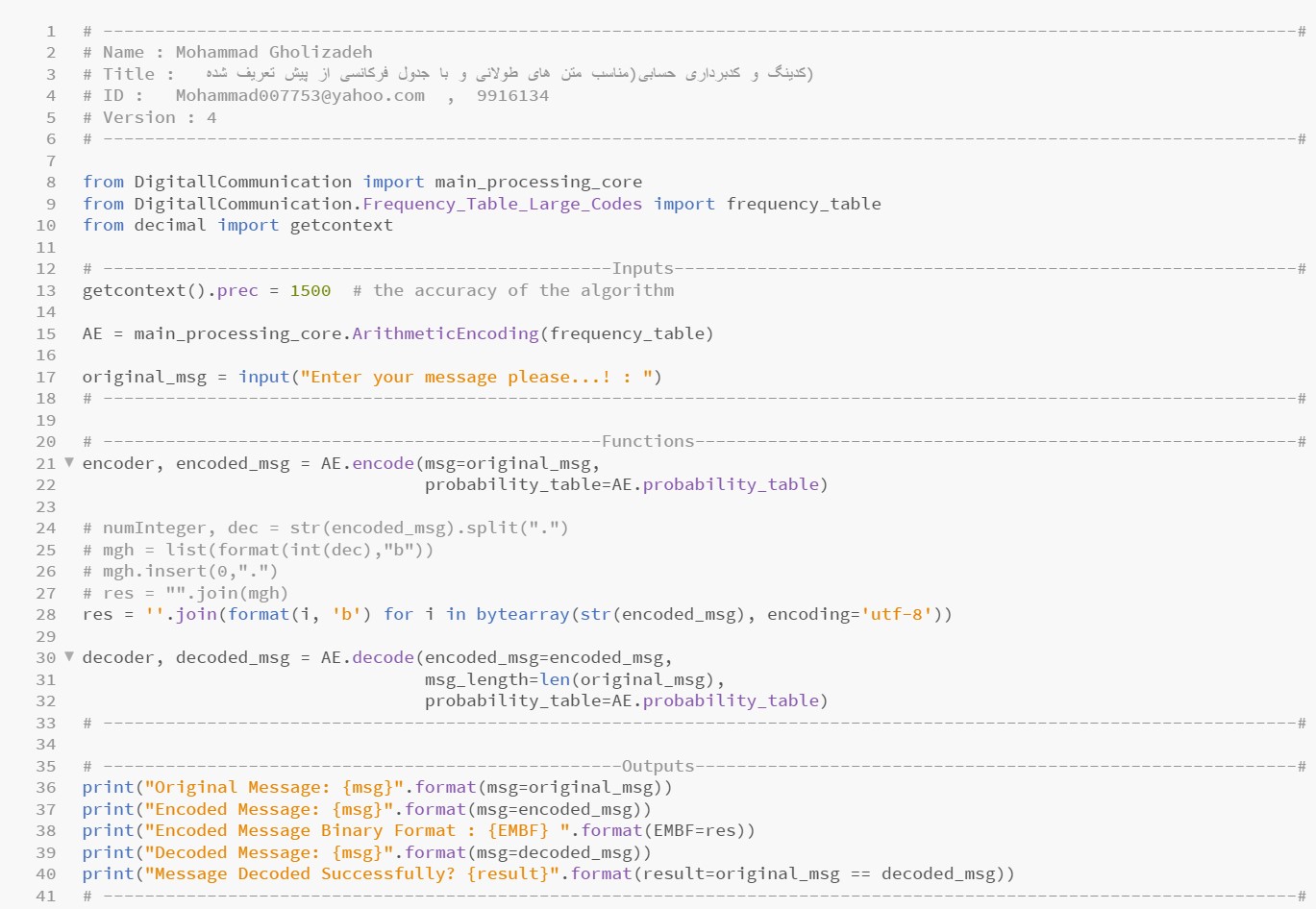
Part of the Python code related to arithmetic coding and decoding for frequency table with large codes:
The Python code related to Arithmetic Encoding:

The Python code related to Arithmetic Decoding:
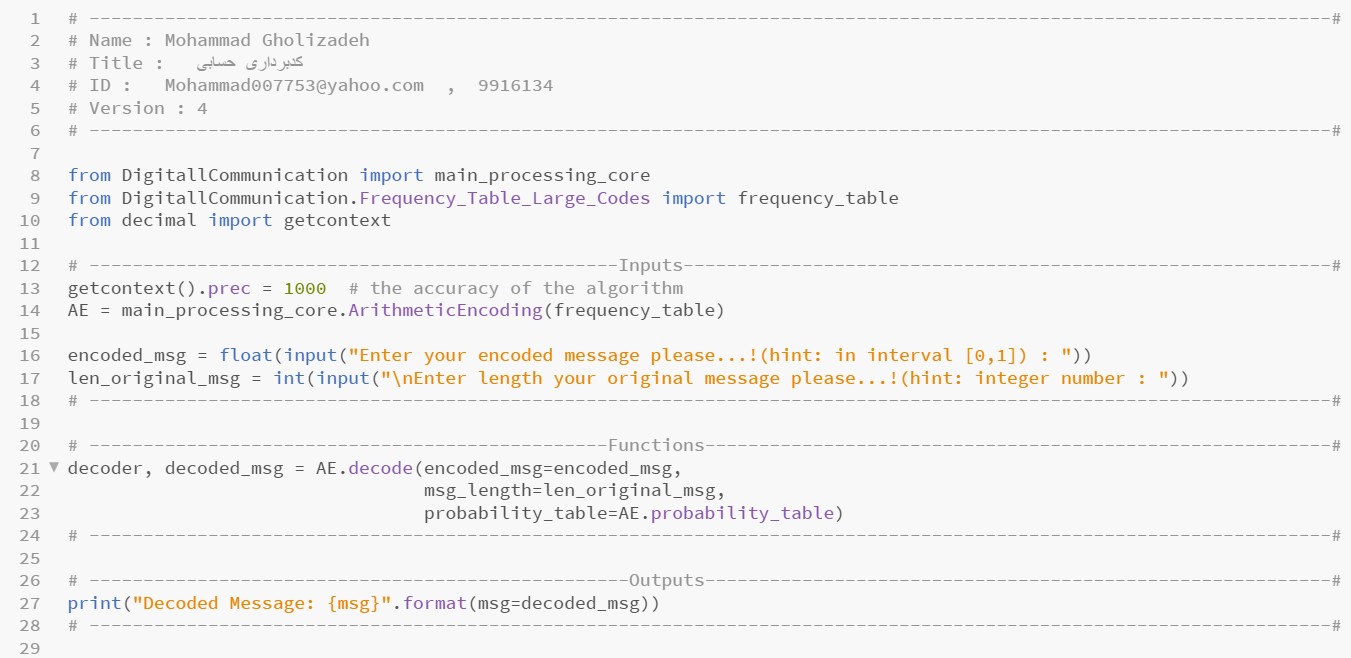
The application window for small codes with a predefined frequency table:
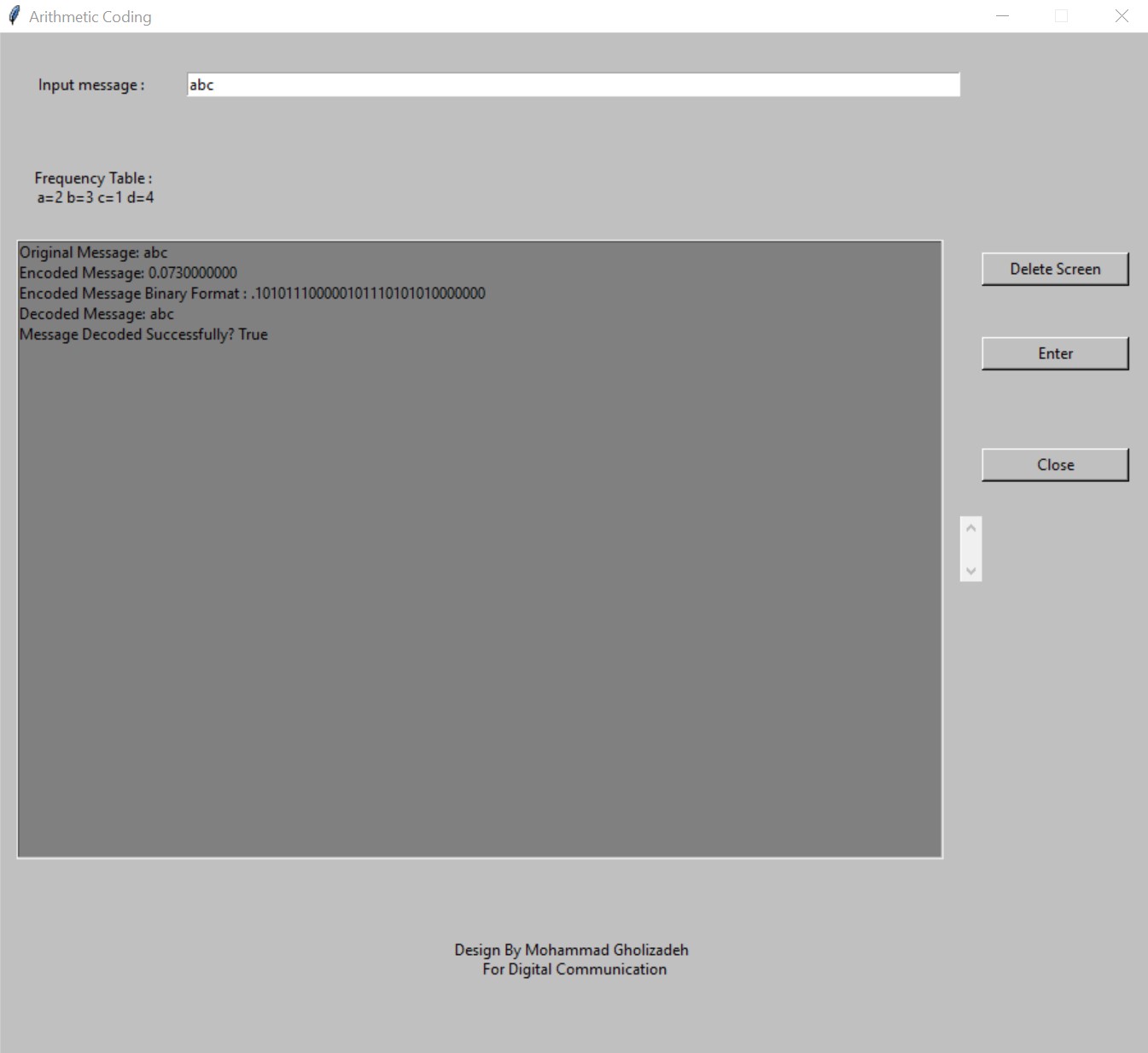
The application window for large codes: